


Partager cet article
ChatGPT : sortir de la sidération

Avocats et magistrats vont-ils bientôt être remplacés par des robots ? Depuis quelques semaines, chacun imagine ce que pourrait être une justice confiée aux robots. Certains s’en effraient, quand d’autres s’en réjouissent. Et si l’on dissipait les fantasmes ? Yannick Meneceur, magistrat en disponibilité et maître de conférences associé en droit numérique à l’Université de Strasbourg ramène l’IA à sa juste place.

Ravivant « l’effet ELIZA[1] », ChatGPT nous aura plongés durant ces derniers mois dans un état remarquable de stupéfaction. Même si le concepteur d’ELIZA, Joseph Weizenbaum, avait pourtant lui-même pris le soin de déconstruire (et critiquer) les effets de son imitation de psychothérapeute rogérien, même si des générations de philosophes et d’informaticiens ont aussi ambitionné de nous aider à prévenir durablement tout anthropomorphisme avec des applications de « l’IA », les derniers exploits du système d’intelligence artificielle produit par OpenAI sont venus occuper un incroyable espace médiatique, ravivant tous les lieux communs usuels du domaine.
Entre prophéties d’un remplacement de l’homme par la machine, émerveillement scientiste et discours alarmistes, les réactions n’ont pas manqué pour commenter un événement avant tout marketing. Les juristes eux-mêmes, dont l’instrument premier est le langage, ont cédé à cette effervescence, en explorant de manière plutôt ludique les compétences et limites du robot. Les publications sur les réseaux sociaux de pseudo-consultations juridiques ou de réponse à des cas pratiques ont rapidement empli les fils Twitter et LinkedIn de captures d’écran avec des productions plus ou moins absurdes.
Pourtant, afin d’appréhender avec un peu de rigueur les contours concrets de la « révolution » qui nous est vendue, nous devrions chercher à sortir de cet état de sidération collective en nous interrogeant sur la nature exacte de la chose qui nous est soumise.
Des savoirs sans sources
Gaspard Koenig, dont la grille de lecture libérale est bien connue, a développé dans une chronique parue aux Échos en février 2023[2] une réflexion à contre-courant de cet effet de mode en soulignant une rupture épistémologique majeure : en nous affranchissant de la notion de source pour produire du savoir, nous serions face à une régression historique dans la production de connaissance. Il ne s’agirait donc pas pour Koenig de s’égarer dans de faux débats sur la « fin du travail ou le robot conscient », mais plutôt de se concentrer sur le fait que « les réponses de ChatGPT vont à l’encontre de la démarche scientifique la plus élémentaire » en étant dans l’incapacité de mentionner ses sources. Le philosophe et essayiste se demande d’ailleurs comment il pourrait en être autrement, puisque « le contenu produit est le fruit de corrélations qui échappent à toute décomposition analytique ».
Les réactions n’ont pas manqué. Des chercheurs / consultants / entrepreneurs ont notamment souligné que de tels systèmes n’ont pas vocation à créer de la connaissance, mais à la restituer et que, si on invitait le système le faire, il pouvait même citer ses sources (en admettant que le système pouvait se tromper ou en inventer de temps à autre). La « mémoire associative » des IA génératives de texte serait donc leur première valeur ajoutée, l’interpolation entre deux contextes pouvant produire quelque chose de cohérent mais aussi, parfois, des choses absurdes. D’autres critiques, moins mesurées, accuseront sans détour Koenig de « ne pas savoir de quoi il parle », d’avoir rédigé un article portant sur les LLM sans les avoir utilisés ni « étudié le mode de fonctionnement » et d’être globalement victime d’un biais de confirmation, en collectionnant dans l’actualité les explications allant le sens de sa démonstration. Sans oublier d’autres ordres de remarques accusant les Européens en général, et les Français en particulier, de se tromper de bataille et soulignant qu’il feraient mieux d’embrasser la course à l’innovation pour rattraper leur retard par rapport aux Américains plutôt que de céder à la critique.
De la méthode scientifique au cumul d’ambiguïtés
Deux jours après cette chronique, voici qu’Henry Kissinger, célèbre diplomate américain, accompagné de deux informaticiens de renom (Éric Schmidt, ancien PDG de Google, et Daniel Huttenlocher, doyen du Schwarzman College of Computing au MIT), publient au Wall Street Journal un long article annonçant une révolution intellectuelle[3]. Les trois auteurs s’inscrivent dans la continuité d’une précédente tribune remarquée de l’ancien diplomate publiée en 2018[4], et dressent un constat assez similaire à celui de Koenig : alors que notre méthode scientifique issue des Lumières s’appuie sur l’accumulation de certitudes (entendre la reproductibilité des expériences et le développement de théories), la nouvelle génération « d’IA » générerait des cumuls d’ambiguïtés. Pour les auteurs, opposant « l’âge des Lumières » à « l’âge de l’IA », la construction de connaissances s’envisagerait aujourd’hui de manière radicalement opposée. Nous serions ainsi devenus indifférents à l’explication des phénomènes si l’on arrive à les reproduire de manière satisfaisante[5]. Les auteurs insistent également sur le fait qu’à l’époque des Lumières, la construction des connaissances s’était élaborée avec un cap philosophique clair, alors qu’aujourd’hui ce cap apparaît bien incertain. L’article, qui développe des réflexions bien au-delà de ces constats, explore ensuite les conséquences de ces développements imposant à ce qu’ils appellent « l’homo technicus » de définir le but qu’il souhaite donner à la société.
Là encore, les critiques et exaspérations n’ont pas manqué de s’exprimer, en évoquant par exemple le fait que « ChatGPT ne représente pas l’IA » ou remettant en cause l’autorité de Kissinger pour avoir investi dans la société Theranos[6].
Une approche statistique du langage
Quels enseignements tirer de ces deux tentatives de contre-discours pour ne pas surajouter au bruit ?
Tout d’abord que les techniques de génération automatique de textes ne sont, en général, pas bien comprises. L’acronyme GPT (pour Generative Pre-trained Transformer) désigne un modèle d’apprentissage profond particulier de traitement de langage naturel dénommé de Large Language Models (LLM), qui est adapté pour traiter de très grandes quantités de textes sans supervision humaine[7]. Toutes les grandes entreprises du numérique connaissent depuis plusieurs ces années ces techniques, déjà appliquées pour prédire, par exemple, les prochains mots lors de la création de messages sur nos téléphones intelligents ou de la saisie de mots-clés dans les barres des moteurs de recherche. La capacité de ces modèles à produire, sur la base de la même technique, des textes entiers crédibles était aussi connue. Mais tant Google que Meta y ont vu un important risque de réputation, tant les dérives étaient sensibles (propos radicaux, racistes, xénophobes etc.) et difficiles à limiter[8]. OpenAI a eu la sagacité de limiter ses modèles mis en production avec des filtres conçus par des centaines de travailleurs bien humains[9] pour éviter ces dérives[10]. Il s’agit donc d’abord d’une approche statistique du langage qui n’a pas, en tant que telle, la vocation ou la capacité de produire de la connaissance.
Toutefois, et c’est le second enseignement à en tirer, « l’effet ELIZA » nous conduit inévitablement, par une forme tout à fait banale d’anthropocentrisme, à attribuer à ces enchevêtrements massifs de corrélations des étincelles d’humanité ou des capacités tout à fait surévaluées. Un peu comme si, sortant d’un tour d’illusionnisme, on commençait à disserter sur l’avènement prochain de la lévitation, de la téléportation ou d’une évolution de l’intelligence des chevaux vers l’intelligence humaine[11].
La complexité ne produit pas de l’intelligence
Non, la complexité ne produit pas de l’intelligence. Et c’est là où la critique de Koenig et Kissinger porte. Les ingénieurs, techniciens et spécialistes du domaine ayant autorité ont l’extraordinaire responsabilité de nous aider collectivement de nous guider afin de ne pas nous égarer dans des spéculations de la « courbe de la hype de Gartner ». Voilà qui aiderait à évacuer les masses de discours inutiles d’individus atteints du syndrome Dunning-Kruger, prêts à remplacer les causalités par les corrélations des « IA ».
En ce sens, Yann LeCun[12] avertit bien sur l’application des « transformeurs[13] » et entrevoit plutôt des applications pour l’aide à la rédaction que la constitution de textes entiers. Ici encore, au mépris de l’autorité scientifique incontestable de LeCun, des critiques lui opposeront sa qualité de salarié de chez Meta, avançant que ceux-ci se sont fait dépasser technologiquement par OpenAI (ce qui est d’ailleurs factuellement faux puisqu’OpenAI a essentiellement employé des briques disponibles pour l’ensemble de la communauté, dont les modèles « transformeurs » pré-entraînés par Google, eux-mêmes inspirés de travaux de Yoshua Bengio).
Alors oui, des développeurs semblent aujourd’hui satisfaits de trouver dans ChatGPT un accélérateur d’écriture pour leurs programmes informatiques. Mais il faut bien comprendre que la modélisation de langages informatiques, par nature non ambigus et structurés, avec un nombre limité de termes, se prête plutôt bien à l’exercice. De même, sans traiter de la question de la propriété intellectuelle, la création artistique, ouverte à l’originalité et sans attente particulière d’un résultat valide, est un domaine où ces générateurs démultiplient les possibilités textuelles, graphiques et sonores, peut-être même jusqu’à la saturation.
Mais pour des professions, comme pour les juristes, où l’exactitude du résultat importe, comment s’en sortir parmi les discours de tous les experts de l’instant ? Est-ce que ces applications ont la capacité de produire une valeur ajoutée pour leur activité quotidienne ? Le modeste apport de cet article aux débats sera de vous offrir un très simple arbre de décision, pour vous aider, ex ante, à répondre à la question « Est-ce sûr d’utiliser ChatGPT pour… ? ».
En espérant que le juge colombien ayant cité dans ses motivations des passages générés par ce robot conversationnel, afin d’accélérer son temps de rédaction et de booster sa productivité, a ainsi fait preuve d’introspection avant de chercher à provoquer son auditoire[14].
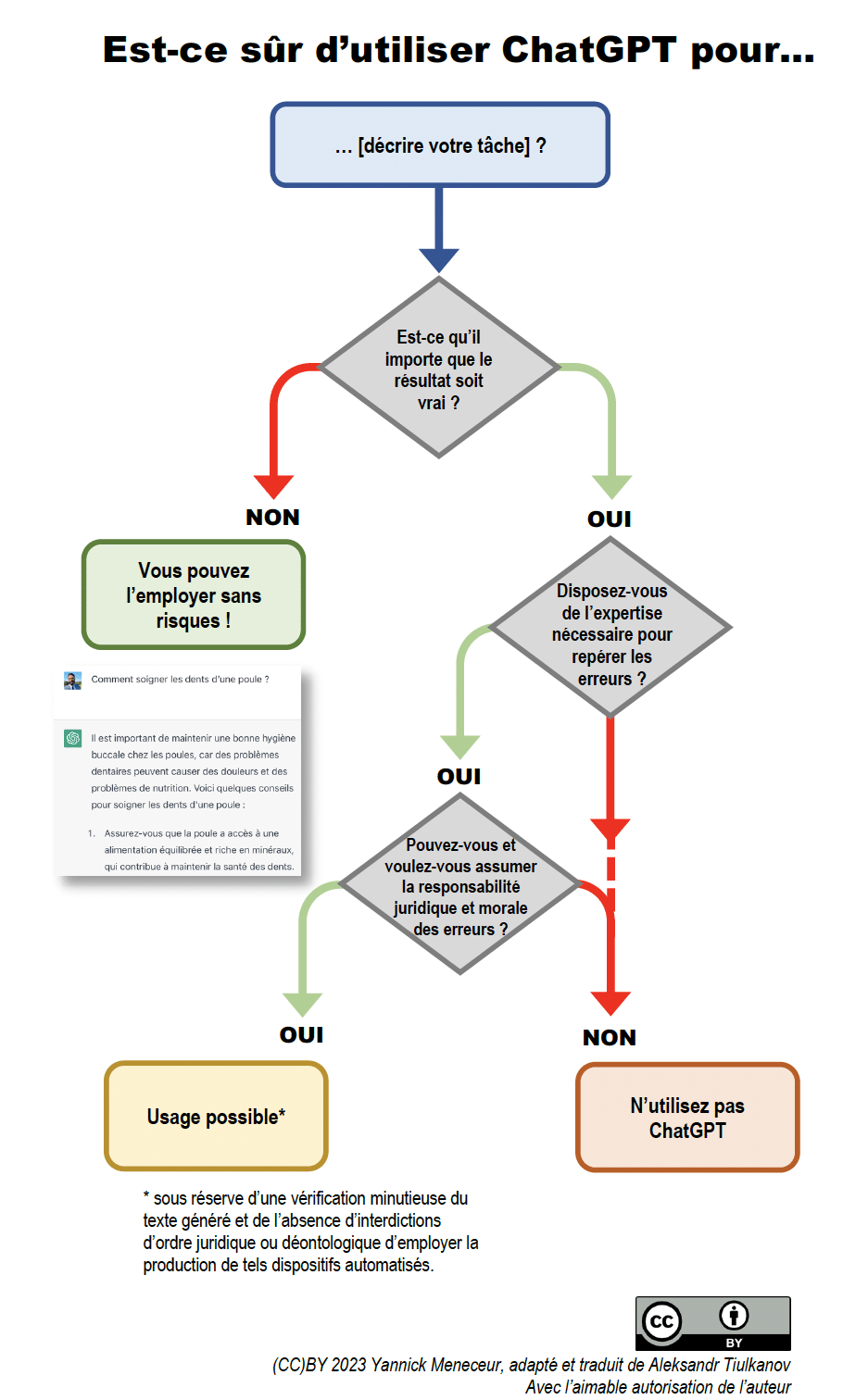
[1] Nom de l’un des tout premier agent conversationnel, élaboré en 1966 par Joseph Weizenbaum. L’effet décrit le biais consistant à assimiler de manière inconsciente le comportement d’un ordinateur à celui d’un être humain.
[2] G. Koenig, La faillite épistémologique de ChatGPT, Les Échos, 22 février 2023
[3] H. Kissinger, E. Schmidt, D. Huttenlocher, ChatGPT Heralds an Intellectual Revolution, The Wall Street Journal, 24 février 2023
[4] H. Kissinger, How the Enlightenment Ends, The Atlantic, juin 2018
[5] Réflexion à mettre en relation avec l’annonce à la fin des années 2000 de la fin de la théorie scientifique avec le Big Data : C. Anderson, The End of Theory: The Data Deluge Makes the Scientific Method Obsolete, 23 juin 2008
[6] Theranos était une entreprise américaine dans le domaine des technologies de la santé dont les dirigeants ont été inculpés en 2018 pour fraude massive.
[7] L’émergence des modèles « transformeurs » ou auto-attentifs est attribuée aux équipes de recherche de Google, inspirés par des premiers travaux de Yoshua Bengio : J. Uszkoreit et al., Attention is All You Need, 6 décembre 2017, accessible sur : https://arxiv.org/pdf/1706.03762.pdf, consulté le 26 février 2023
[8] V. par exemple l’ancienne expérience de Microsoft sur Twitter : V. Hermann, Tay, une IA lancée par Microsoft sur Twitter puis retirée pour aliénation mentale, Next Inpact, 24 mars 2016
[9] B. Perrigo, Exclusive: OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic, Time, 18 janvier 2023
[10] Microsoft, qui cherche à faire passer les acquis d’OpenAI en production, s’est à nouveau confronté à ces difficultés. V. par exemple K. Roose, Why a Conversation With Bing’s Chatbot Left Me Deeply Unsettled, The New York Times, 17 février 2023
[11] Lire à cet effet l’introduction de l’ouvrage de Kate Crawford, l’histoire du cheval « Hans le malin » : K. Crawford, Atlas of AI, Yale University Press, 2021
[12] Récipiendaire du prix Turing 2019 pour ses travaux sur l’apprentissage profond avec Geoffrey Hinton et Yoshua Bengi
[13] A. Gayte, ChatGPT vous impressionne ? Yann LeCun s’en fiche, Numerama, 25 janvier 2023
[14] J. Rose, A Judge Just Used ChatGPT to Make a Court Decision, 3 février 2023
Référence : AJU353292